
Overview
Oracle Data Mining (ODM) is a component of the Oracle Advanced Analytics Database Option. ODM contains a suite of advanced data mining algorithms that are embedded in the database that allows you to perform advanced analytics on your data.
Oracle Data Miner is an extension of Oracle SQL Developer, a graphical development environment for Oracle SQL. Oracle Data Miner uses the data mining technology embedded in Oracle Database to create, execute, and manage workflows that encapsulate data mining operations. The architecture of ODM is illustrated in figure 1.

Figure 1: Oracle Data Mining Architecture for Big Data
Algorithms are implemented as SQL functions and leverage the strengths of the Oracle Database. The SQL data mining functions can mine transactional data, aggregations, unstructured data i.e. CLOB data type (using Oracle Text) and spatial data.
Each data mining function specifies a class of problems that can be modeled and solved. Data mining functions fall generally into two categories: supervised and unsupervised.
Notions of supervised and unsupervised learning are derived from the science of machine learning, which has been called a sub-area of artificial intelligence.
Supervised learning is also known as directed learning. The learning process is directed by a previously known dependent attribute or target. Directed data mining attempts to explain the behavior of the target as a function of a set of independent attributes or predictors.
Unsupervised learning is non-directed. There is no distinction between dependent and independent attributes. There is no previously-known result to guide the algorithm in building the model. Unsupervised learning can be used for descriptive purposes.
Oracle Data Mining Supervised Algorithms
| Technique | Applicability | Algorithms (Brief description) |
|---|---|---|
Classification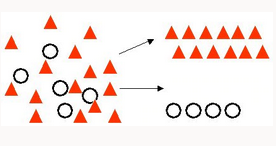 | Most commonly used technique for predicting a specific outcome for example Cancer tumour cells identification, Sentiment analysis, Drugs classification, spam detection. | Generalized Linear Models Logistic Regression - classic statistical technique available inside the Oracle Database in a highly performant, scalable, parallized implementation (applies to all OAA ML algorithms). Supports text and transactional data (applies to nearly all OAA ML algorithms) Naive Bayes - Fast, simple, commonly applicable. Support Vector Machine - Machine learning algorithm, supports text and wide data. Decision Tree - Popular ML algorithm for interpretability. Provides human-readable "rules". |
Regression | Technique for predicting a continuous numerical outcome such as Astronomical data analysis, Generating insights on consumer behavior, profitability, and other business factors, Calculating causal relationships between parameters in biological systems. | Generalized Linear Models Multiple Regression - classic statistical technique but now available inside the Oracle Database as a highly performant, scalable, parallized implementation. Supports ridge regression, feature creation and feature selection. Supports text and transactional data. Support Vector Machine - Machine learning algorithm, supports text and wide data. |
Attribute Importance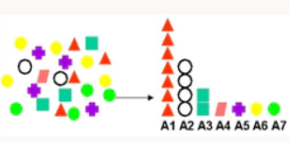 | Ranks attributes according to strength of relationship with target attribute. Use cases include finding factors most associated with customers who respond to an offer, factors most associated with healthy patients. | Minimum Description Length - Considers each attribute as a simple predictive model of the target class and provides relative influence. |
Oracle Data Mining Unsupervised Algorithms
| Technique | Applicability | Algorithms |
|---|---|---|
Clustering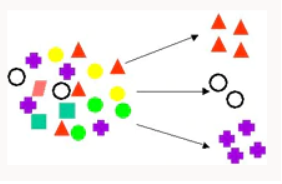 | Clustering is used to partition a database's records into subsets or clusters where elements in a cluster share a set of common properties. Examples include finding new customer segments, and Movie recommendations. | K-Means - Supports text mining, hierarchical clustering, distance based. Orthogonal Partitioning Clustering - Hierarchical clustering, density based. Expectation Maximization - Clustering technique that performs well in mixed data (dense and sparse) data mining problems. |
Anomaly Detection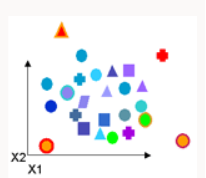 | Anomaly detection identifies data points, events, and/or observations that deviate from a dataset’s normal behavior. Common examples include bank fraud, a structural defect, medical problems or errors in a text | One-Class Support Vector Machine - trains untagged data and tries to determine whether a test point belongs to the distribution of training data. |
Feature Selection and Extraction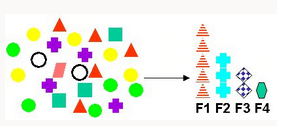 | Produces new attributes as linear combination of existing attributes. Applicable for text data, latent semantic analysis (LSA), data compression, data decomposition and projection, and pattern recognition. | Non-negative Matrix Factorization - Maps the original data into the new set of attributes Principal Components Analysis (PCA) - creates new fewer composite attributes that respresent all the attributes. Singular Vector Decomposition - established feature extraction method that has a wide range of applications. |
Association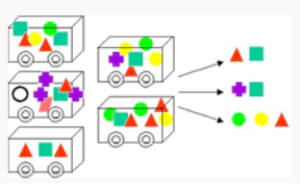 | Finds rules associated with frequently co-occuring items, used for market basket analysis, cross-sell, root cause analysis. Useful for product bundling and defect analysis. | Apriori - Hashed a tree to collect information in a database |
Enabling the Oracle Data Mining Option
From 12c Release 2 the Oracle Advanced Analytics Option includes Data Mining and Oracle R functionality.
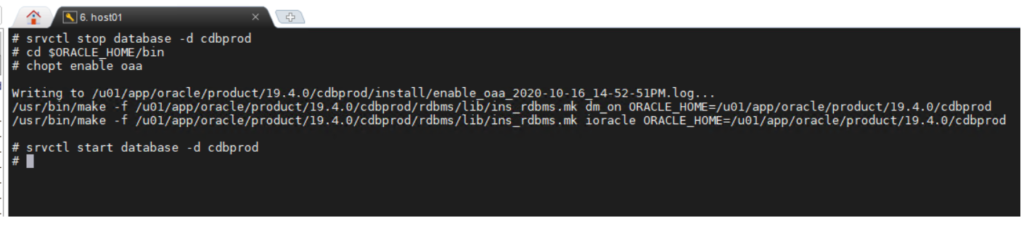
The Oracle Advanced Analytics option is enabled by default during installation of Oracle Database Enterprise Edition. If you wish to enable or disable a database option, you can use the command-line utility chopt.
chopt [ enable | disable ] oaa
To enable the Oracle Advanced Analytics option:
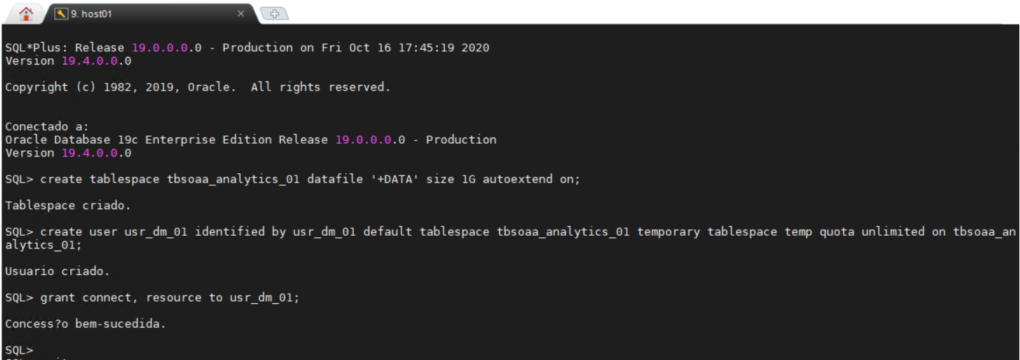
Creating Tablespace an ODM Schema
All users require a permanent tablespace and a temporary tablespace in which to do their work, it can be very userful to have a separate area in your database where you can create all your data mining objects.
The usr_dm_01 schema will contain all your Data Mining works.
Creating the ODM Repository
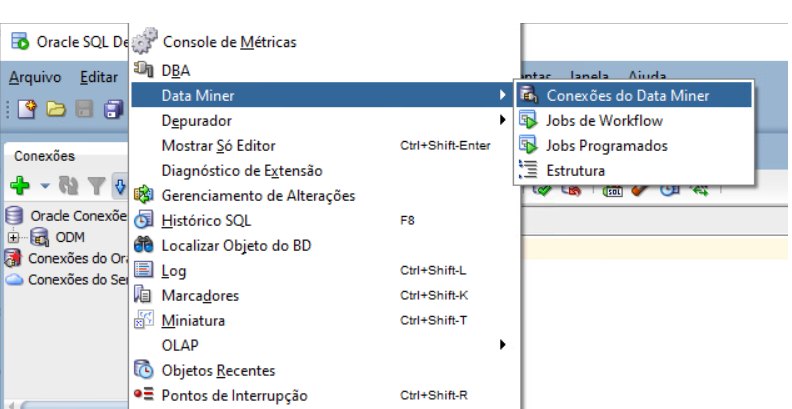
You need to create an Oracle Data Mining Repository in the database. Go to Data Miner Navigator in SQL Developer.
Select View -> Data Miner -> Data Miner Connections:
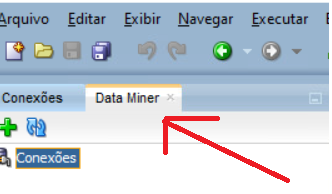
A new tab opens beside your existing Connections tab:
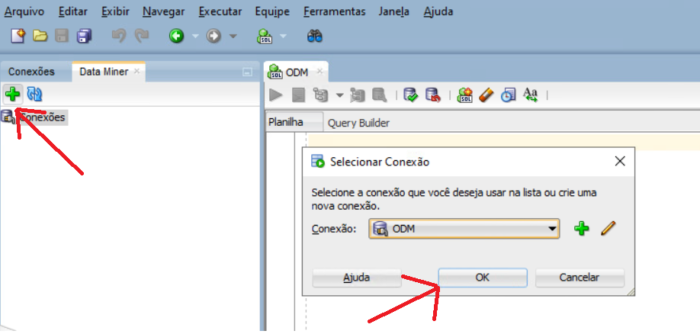
To add usr_dm_01 schema to this list, click on the green plus windows and OK
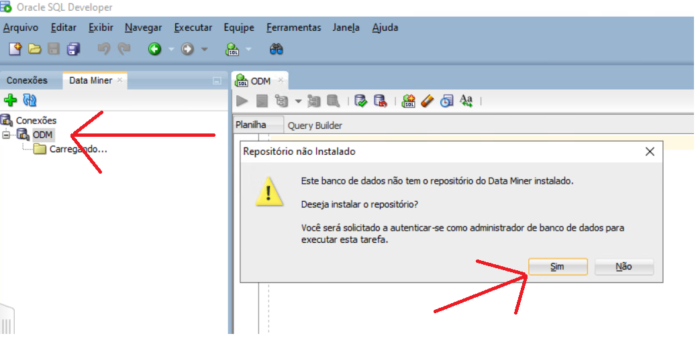
If the repository does not exist a message display asking whether you would like to install the repository. Click the Yes button to proceed with the install.
You need to enter the SYS password
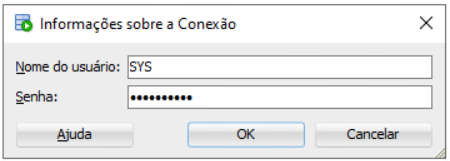
Repository Installation Setting
Install Data Miner Repository progress window
Task Completed Successfully
Log File
Oracle Data Mining Components
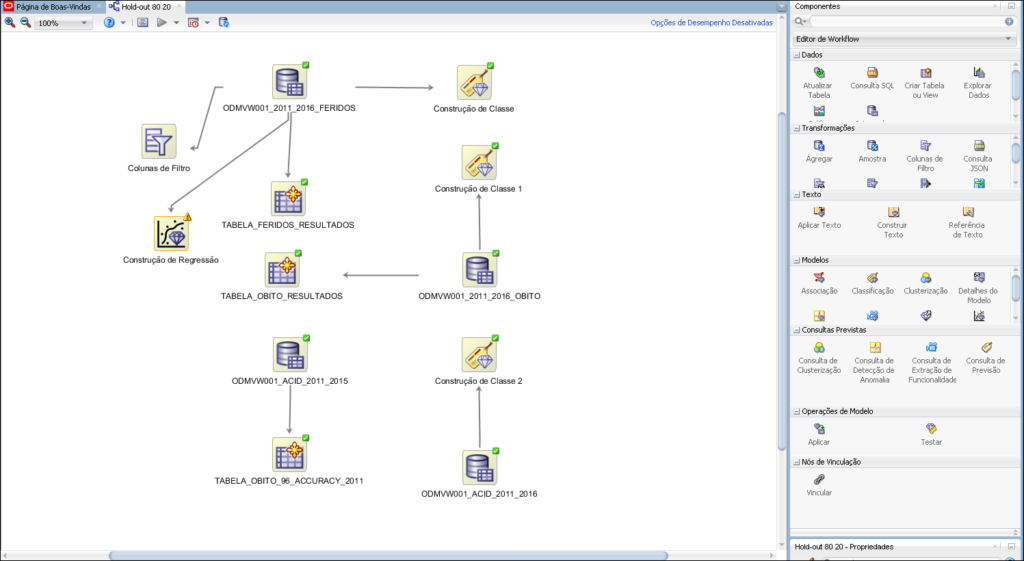
The workflow allows you to build up a series of node that perform all the required processing on your data.
Example of a workflow developed for predictive analytics
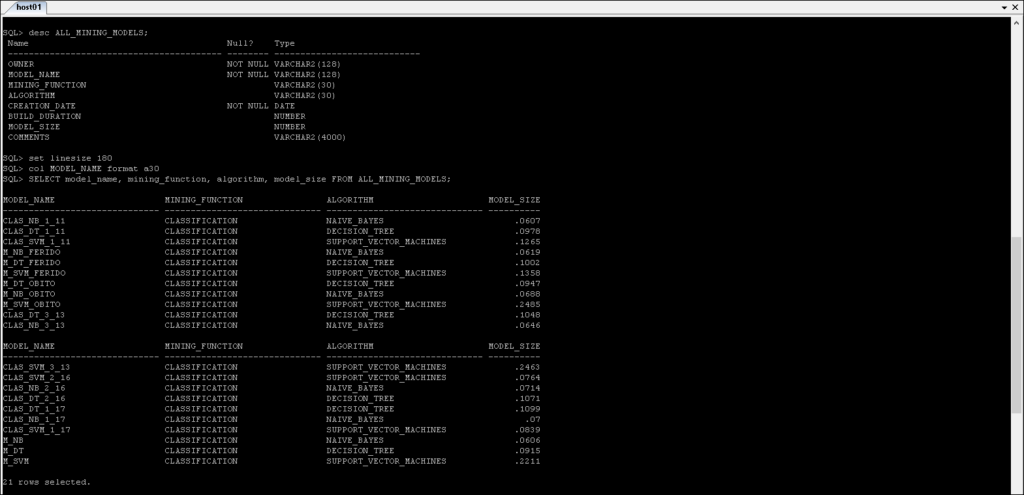
ODM Data Dictionary Views
You can obtain information about mining models from the data dictionary.
The Data Mining data dictionary views are summarized as follows:
Note: * can be replace by ALL_, USER_, DBA_ and CDB_
*_MINING_MODELS: Information about the mining models that have been created.
*_MINING_MODEL_ATTRIBUTES: Contains the details of the attributes that have been used do create the Oracle Data Mining model.
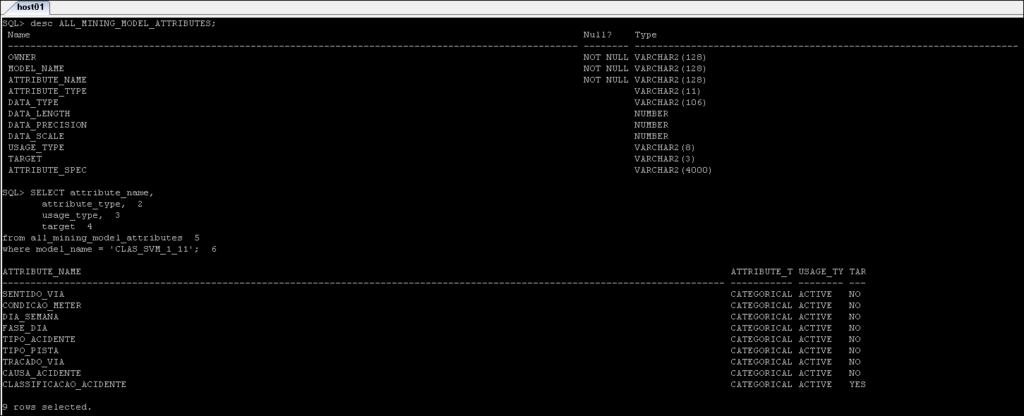
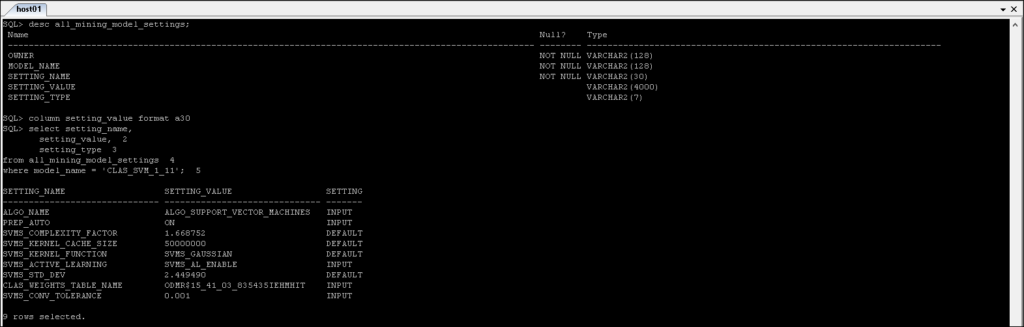
*_MINING_MODEL_SETTINGS: Returns information about the settings for the mining models to which you have access.
References
Oracle Data Mining User’s Guide. Available at: https://docs.oracle.com/en/database/oracle/oracle-database/19/dmprg/lot.html
Oracle Data Mining – Scalable in-database predictive analytics. Available at: https://www.oracle.com/database/technologies/advanced-analytics/odm.html
Oracle Data Miner System Overview. Available at: https://docs.oracle.com/database/sql-developer-17.4/DMRIG/oracle-data-miner-overview.htm#DMRIG124